LayerDiffuse - AI 生成透明图像
今天我看了一个生成透明背景图像的SD扩展。这篇论文是上个月底由斯坦福实验室发布的。

https://arxiv.org/abs/2402.17113
简介
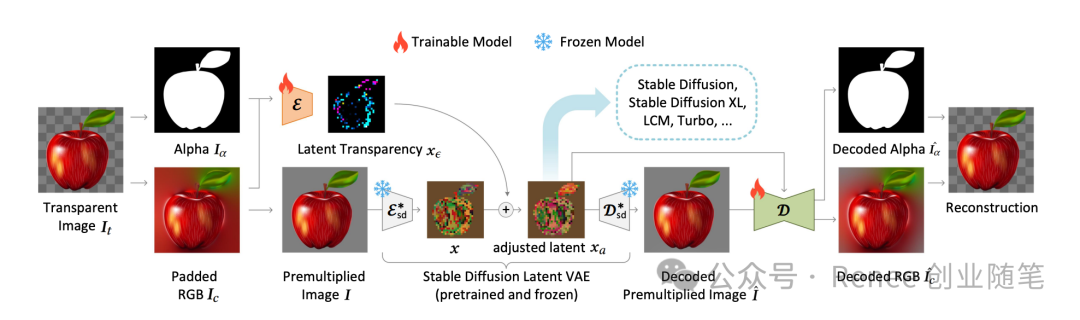
LayerDiffuse使大规模预训练的潜在扩散模型能够生成透明图像。该方法允许生成单个透明图像或多个透明层。该方法学习了一个“潜在透明度”,它将alpha通道的透明度编码到预训练潜在扩散模型的潜在流形中。通过以潜在偏移的形式调节添加的透明度,它保持了大型扩散模型的生产就绪质量,对原始预训练模型的潜在分布的改变保持在最小。通过这种方式,任何潜在扩散模型都可以通过微调调整后的潜在空间,转变为透明图像生成器。
使用效果
在Stable Diffusion的WebUI(Forge版本)中可以使用LayerDiffuse,ComfyUI也有社区成员贡献的workflow。目前,官方提供的示例主要是针对文生成图的应用,图生成图的功能尚未推出。
使用场景
仅生成透明图像(注意力注入):这个场景仅专注于生成具有透明度的前景物体,而不需要任何前景或背景的文本或图像提示。
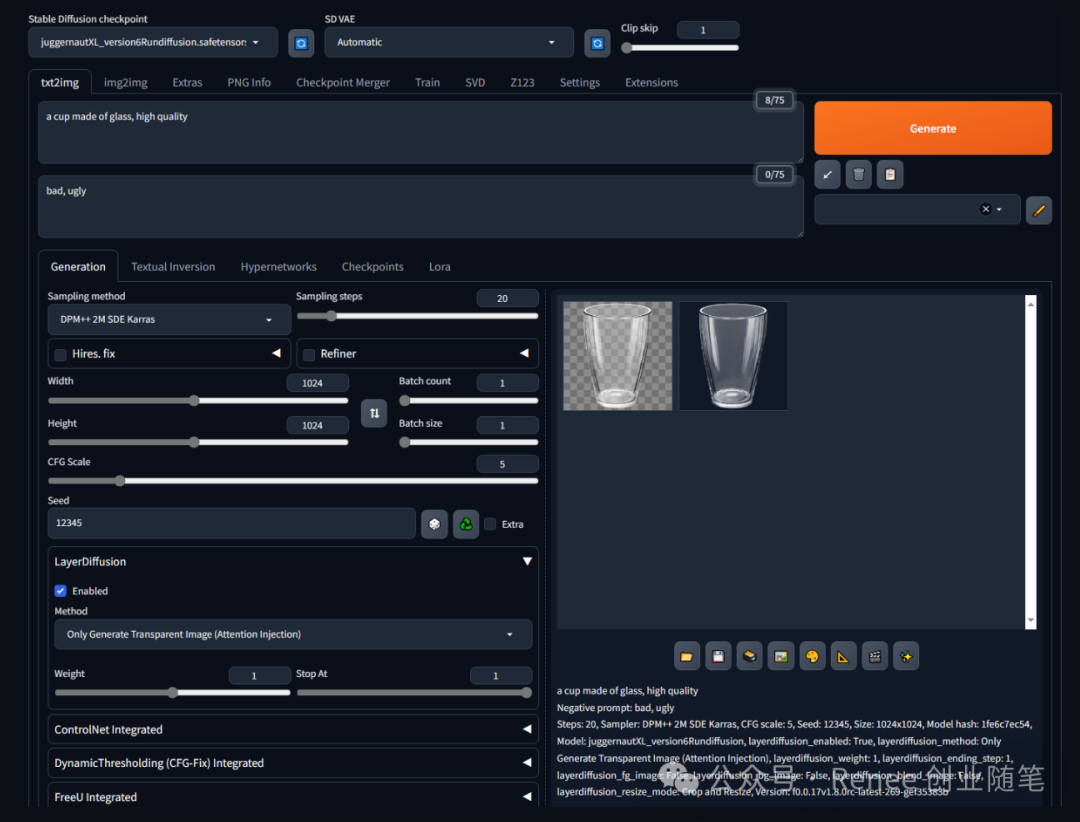
同时生成全部元素:在这个场景中,模型根据提供的前景、背景和混合图的文字提示来生成一个完整的图像,同时输出透明的前景物体、背景图和混合图。
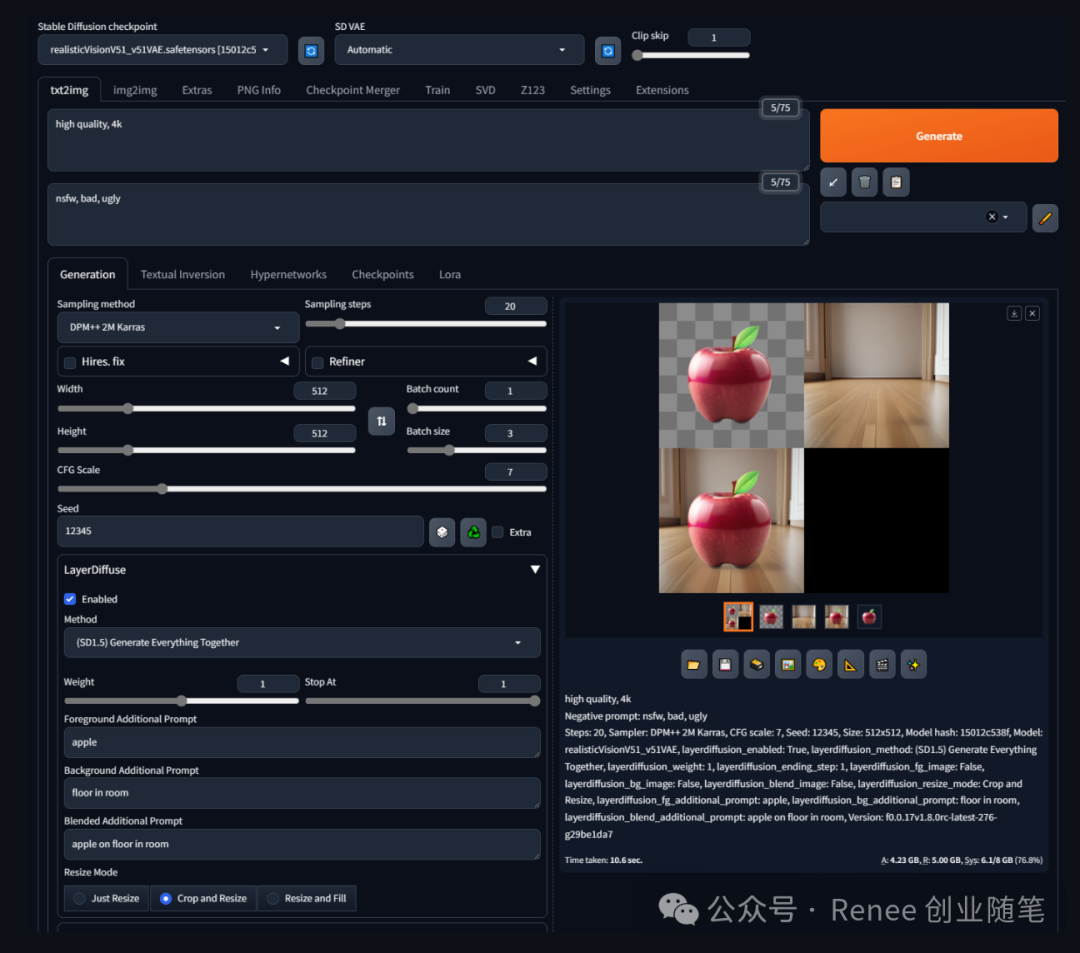
从背景到混合图生成:这里,模型使用背景图的图像来生成混合图,不涉及前景物体或混合图的直接生成。
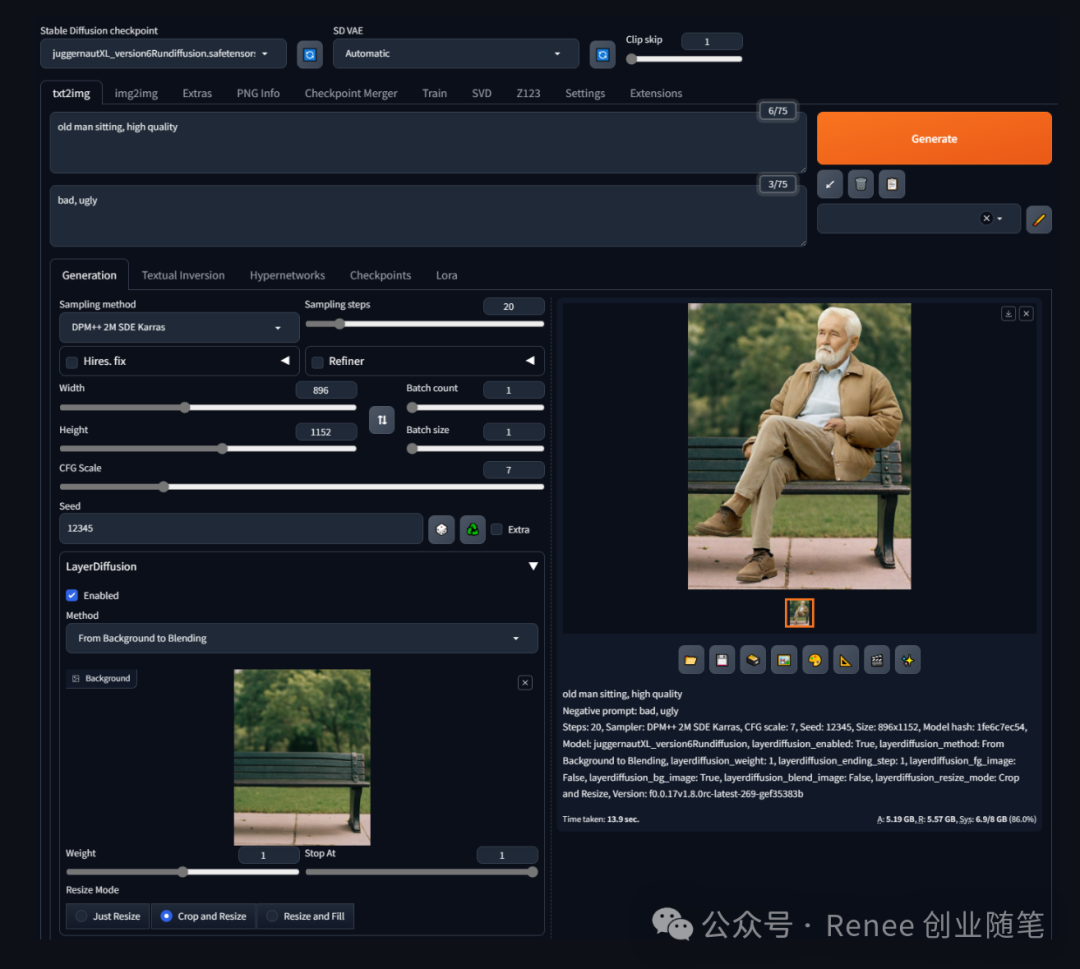
从前景到混合图生成:在此场景中,模型根据前景物体的图像提示生成混合图,但不直接生成背景图。
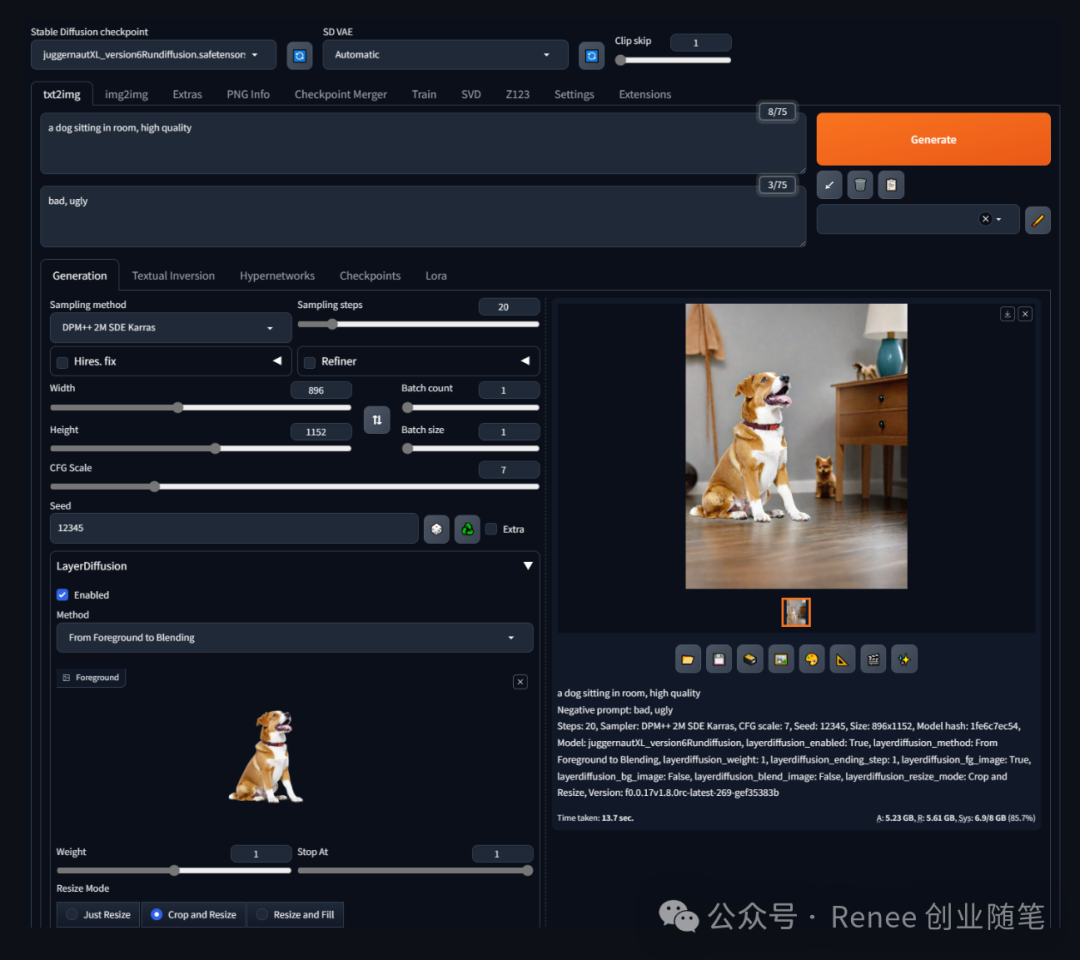
从背景到前景生成:模型接收背景的文字提示和前景的图像提示,然后生成前景物体和混合图,同时保留对前景物体透明度的处理能力。
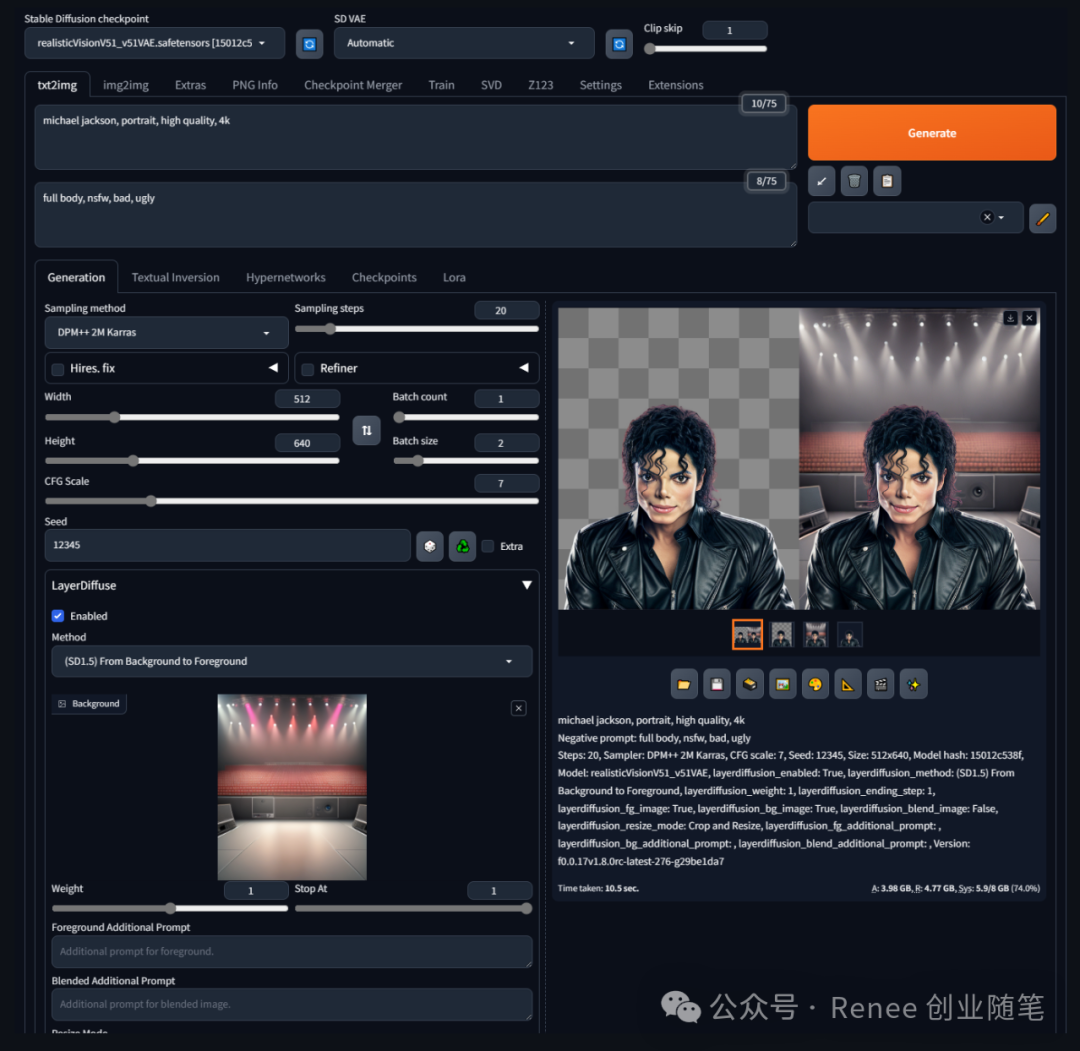
从背景和混合图到前景生成:此场景下,模型利用背景和混合图的图像提示来生成前景物体,专注于前景的透明度处理。
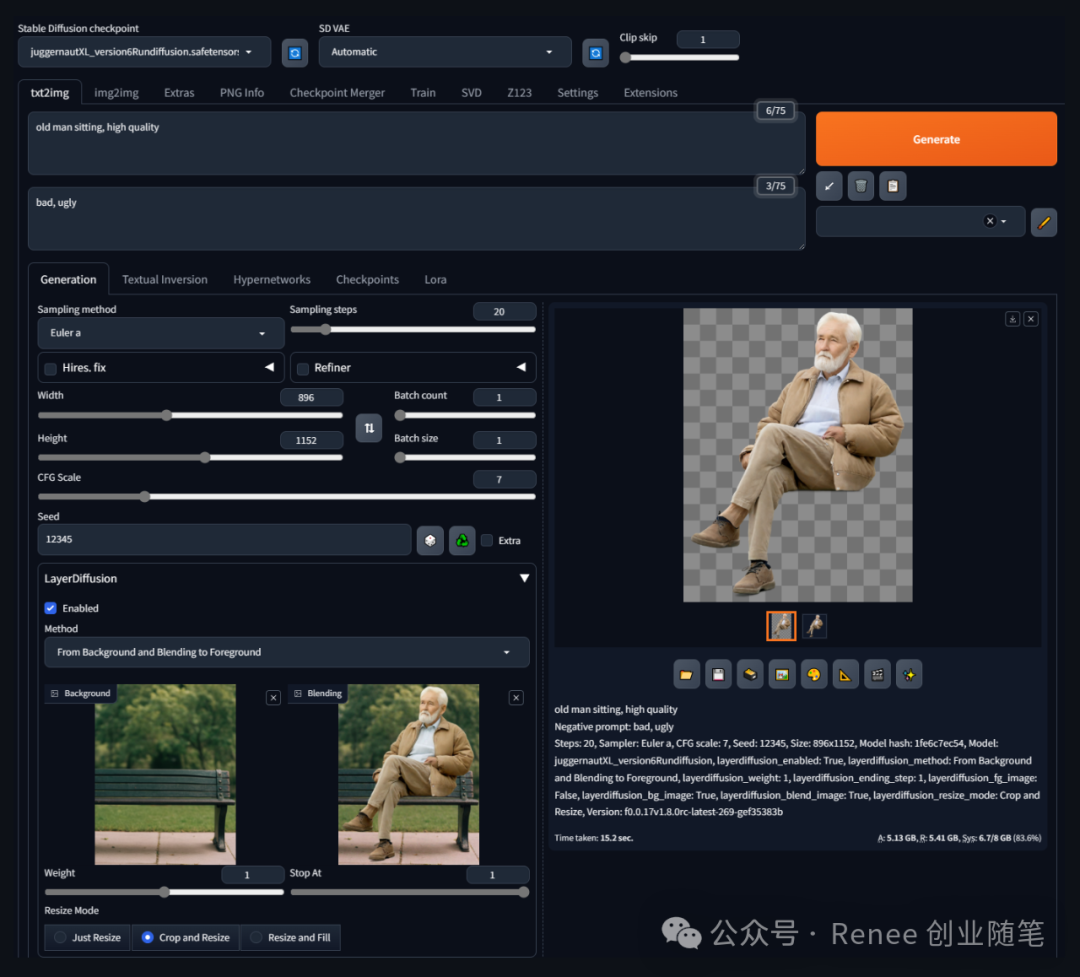
从前景到背景生成:模型使用前景物体的图像和背景的文字提示来生成背景图和混合图,没有直接生成透明的前景物体。
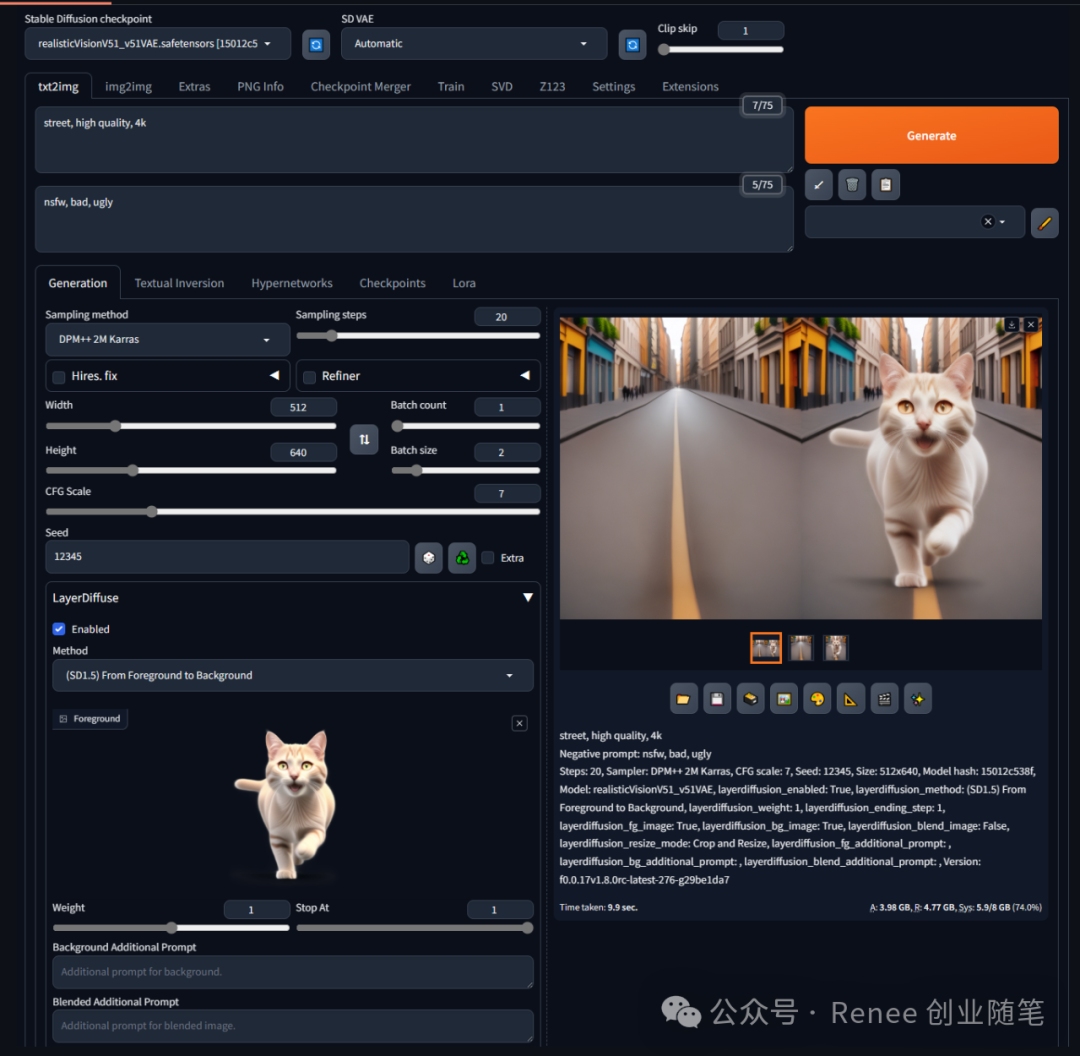
从前景和混合图到背景生成:在这个场景下,模型根据前景和混合图的图像提示生成背景图,未直接处理透明前景物体的生成。
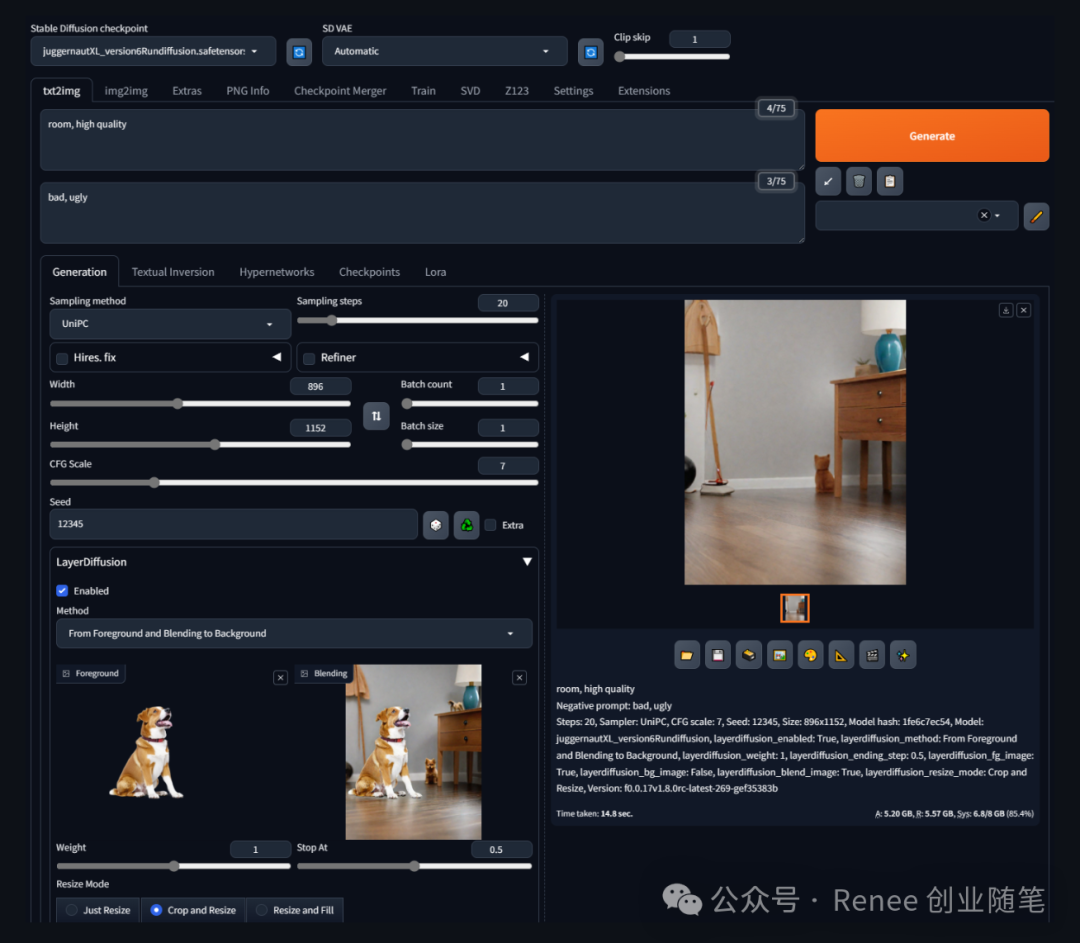
技术细节
使用人类参与的循环收集方案收集了100万对透明图像层配对来训练模型。LayerDiffuse展示了潜在透明度可以应用于不同的开源图像生成器,或适应于各种条件控制系统以实现应用,如前景/背景条件下的层生成、联合层生成、层内容的结构控制等。
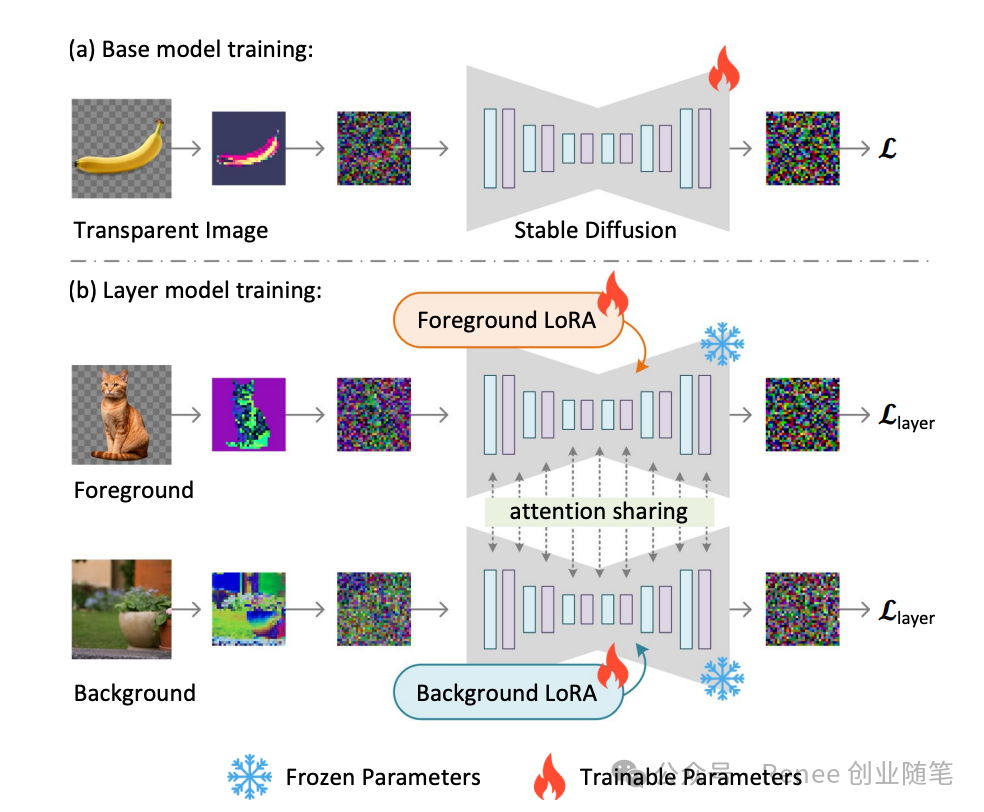
框架接收一个输入的透明图像,并编码一个“潜在透明度”以调整Stable Diffusion的潜在空间。调整后的潜在图像可以被解码,以重构颜色和alpha通道。这种带有透明度的潜在空间可以进一步用于训练或微调预训练的图像扩散模型。
对比

97%的情况下,用户更喜欢LayerDiffuse原生生成的透明内容,而不是之前的临时解决方案,如生成然后抠图。
用户还报告说,LayerDiffuse生成的透明图像的质量与真实的提供透明背景的商业图片库(如Adobe Stock)相媲美。